2013-02-22-Bayes
Table of Contents
1 Classification: Bayes
2 Confusion Matrix
- What are the ways that classification can be wrong?
| Predict: Positive | Predict: Negative | |
| Actual: Positive | True Positive | False Negative |
| Actual: Negative | False Negative | True Negative |
2.1 Obtain Data notes
- How do we obtain this data?
3 Testing Data two_col
- Data used to test a learned model
- Test data was not used to learn
- Where does test data come from?

3.1 Not from storks notes
4 Training Data
- Set aside a portion of training data to test with
- Test data:

4.1 Set Aside Testing

Testing Data | Training Data
4.2 Colors notes
- Red: Testing
- Green: Training
4.3 Cross Validation

Train and test model with different subsets of data
4.4 Testing the model notes
- This is used to test the model
- How well does it perform with a variety of inputs?
- Is it robust against outliers
4.5 K-Fold Validation

Test against K sections of the data
4.6 Statistical Significance notes
- Similar to the concept in stats: the more distinct samples you have, the better you know your data
4.7 K-Fold Validation

5 Bayes Theorem
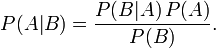
Can calculate a posterior given priors
5.1 Read notes
- Probability of A given B equals probability of B given A times prob of A divided prob of B
- Importance is that we can figure out what future probabilities are based on what we've already seen
6 Spam
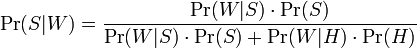
Find the probability of spam given it contains a particular word
6.1 Words notes
- What words would you associate with spam?
- Are these the same across all people?
- Why might you want to train a classifier per person?
7 Multiple Words animate
- How to calculate probabilities of multiple independent events occurring?
- Model words as independent events
- Multiply probabilities
7.1 Naive notes
- Words are not independent
- San? Francisco is more likely
- But works suprisingly well in practice
8 Practical concerns animate
- What is the probability of a word we've never seen before?
- Underflow: multiplying numbers still everything is rounded to 0
- Normalizing words: v1agra
8.1 Solutions notes
- divide by 0. Instead, add 1 to all words
- using log of probabilities
- Rules
9 Ensemble
- Using multiple models simultaneously
- Run all classifiers over new data, take majority vote
- Netflix Prize won with combination of models from several teams
9.1 Requirements notes
- Nice thing is that the diversity of models is important, and not so much the accuracy of any single model
10 Bootstrap Aggregating two_col
- Bagging: training data collected with replacement
- Learn models on different samples
- Run models on new incoming data
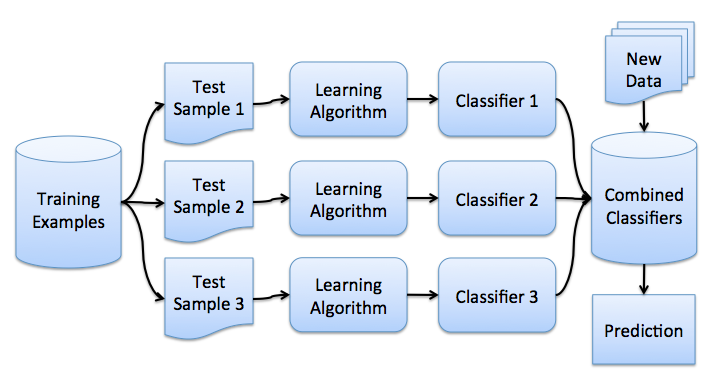
10.1 Trade-offs notes
- Fairly simple:
- Majority vote
- Train models independently
- img: http://cse-wiki.unl.edu/wiki/index.php/Bagging_and_Boosting
11 Boosting
- Train classifier to catch what the last one missed
- Train and test first classifier
- Find classification failures
- Weight more heavily those failures in training a new model
- Weight models by their accuracy
11.1 Trade-offs notes
- Boosting can be susceptible to outliers
- Longer to train
- Observed to be more accurate
12 Many Decision Trees
- Train trees with random selection of attributes, subset of data
- Combine trees using majority or weights
- What to call many arbitrarily picked trees?
12.1 Random Forests two_col

- Used successfully in many recent competitions
- Carry over robustness properties from individual decision trees
- Can be trained in parallel
12.2 Parallel notes
- Potentially good fit for MapReduce paradigms