2013-03-15-Advanced-Cluster
Table of Contents
1 Advanced Clustering
1.1 Questions from last week notes
- Heuristic for choosing # of clusters? root(n/2)
- k-means: how to calculate the centroid?
- k-medoids: how to calculate the medoid?
2 Review
- Clustering groups points by using similarity
- Build up, or break down groups
- Each point belongs to 1 cluster
2.1 Types notes
- Agglomerative, Divisive
- Assign each point to 1 centroid (k-means)
- or assign group clusters together, starting with every point as a cluster (hierarchical)
3 Topics?
- "This place is great. I've been here for meetings, to get work done, to hang out with friends, and on dates, and it's fit the bill every time. In the summer, there's a wonderful patio, and in the winter it's cozy and warm. All the food I've had is delicious – especially the salad dressing!"
3.1 Model by topic notes
- ambiance,
- romantic
- good for work
- food quality
- Many
- So how do we model?
4 Fuzzy Clusters
- Membership is a degree in [0-1]
1 = sum(membership(v,c) for c in clusters)- Every point belongs to at least 1 cluster
4.1 Restrictions notes
- Every point still must be in a cluster
- Think of the degree as a probability
- Probabilities must add up to 100% (1)
5 Generative Model animate
- "Real" model that produced original data points
- Our mission is to reproduce the original model
- Thus we have different techniques that can model different behavior
5.1 Questions notes
- What is a "generative model"?
- What is data mining trying to discover? What is machine learning hoping to reproduce?
- Why have different classifiers? Decision tree, Naive Bayes, etc?
6 HW: 1-D Clustering animate
- Imagine plotting the points on the number line
- I generated these points with a process
- Two Gaussian arrays, concatenated
6.1 Questions notes
- Draw number line
- How did I come up with these numbers? I wanted two clusters.
- What parameters did I use, in the code to generate this specific set of N numbers?
7 Parameters two_col
- Median
- Standard Deviation
- How many points to generate from each
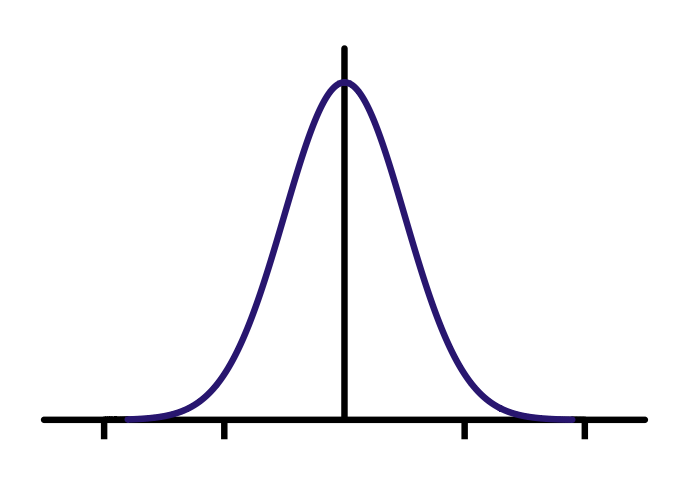
7.1 Translation notes
- I had two distributions (median, stddev)
- Now I picked one or the other with a certain probability
- Then generated a number from it
- In reality, just generated 10 from A, 10 from B, but you can imagine that being 50% 50%
8 Generative Model
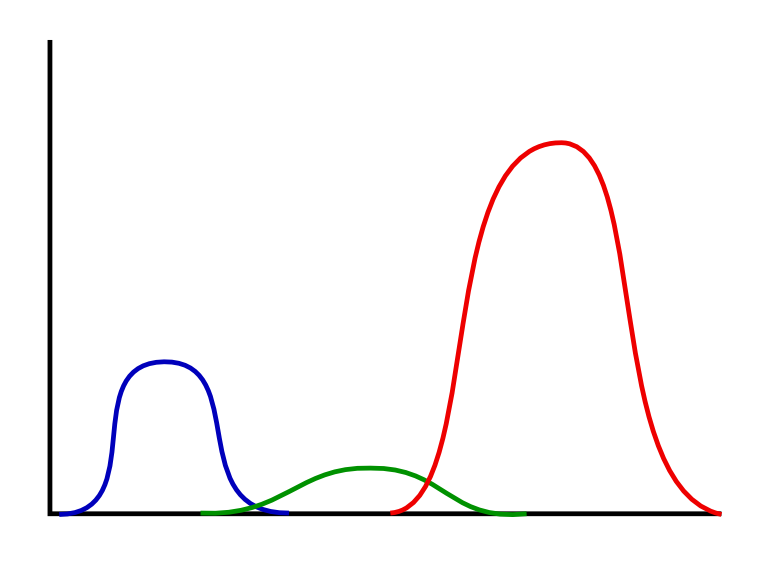
8.1 3 Clusters notes
- We have all three parameters:
- median
- stddev
- probability of choosing distribution (height)
9 Best Fit? two_col
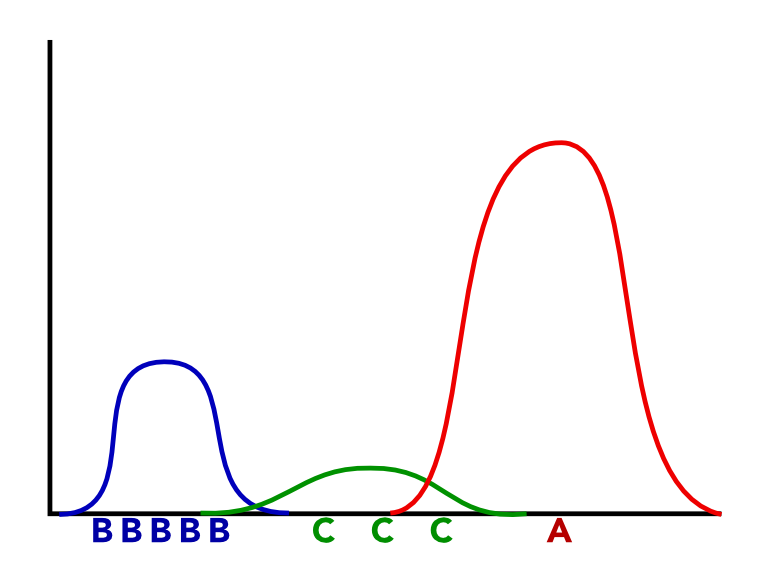
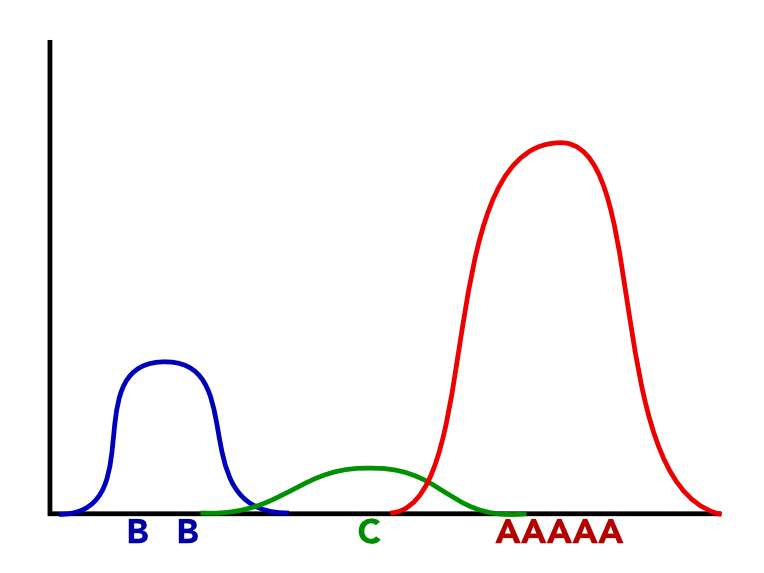
9.1 Choose notes
- These letters are points on our number line
- Which is more likely to be generated by our real model?
- But we don't know the generative model, so how do we discover it?
10 Revisit k-means animate
- Each object assigned to closest cluster
- Reset center of the cluster to average
- Repeat until steady
10.1 Questions notes
- What are the steps of k-means?
11 Expectation-Maximization
- Expectation
- Given current state, create a solution that fits our expectations
- Maximization
- Adjust the state to maximize the likelihood of the solution being true
- Terminate
- When adjustments do not change
11.1 k-means translation notes
- Our expectation in k-means is that points belong to the cluster closest to them
- Our state or parameters for our model are the locations of the centers of those clusters
- The maximization step therefore moves the centers to maximize the likelihood of their being the true center
12 Revisit k-means animate
- Each object assigned to closest cluster
- Reset center of the cluster to average
- Repeat until steady
12.1 Questions notes
- What are the steps of k-means?
13 Fuzzy Clustering
Each object assigned to closest cluster- Each object assigned probability of cluster
Reset center of the cluster to average- Reset center of the cluster to weighted average
- Repeat until steady
13.1 Change notes
- Only difference here is that we're calculating the probability of a point belonging to a cluster
- What should we base that probability off of? distance
- If point A has a high probability of belonging to cluster C, what can you say about A and C? Close
14 Distance
dist(o,C) / sum(dist(o,c) for c in clusters))
14.1 Similarity notes
- Our old friend distance
15 Distance2
dist(o,C)**2 / sum(dist(o,c)**2 for c in clusters))- Squared distance to primary cluster, divided by squared distance to all clusters
15.1 Similarity notes
- Our old friend distance
- And squared, to make sure we stay positive
16 Reset Center
sum(weight[c][p]**2 * p for p in points)- Squared weight for this point in this cluster, multiplied by point coordinates
16.1 Weighting by distance notes
- Distance of point affects how much a cluster center is pulled toward it
17 Stability
- When our centroids stabilize, we can estimate the parameters of our distributions
- Or use probabilities of points directly
17.1 Uses notes
- Sometimes you may not need original parameters